※トリスタinsideに投稿された記事の再掲載です。
 アプリチームのKです。Android版ニコニコ漫画 / 読書メーターの開発を担当しています。
日々アプリの価値向上を目的に様々な機能追加・改善を行っています。色々なサービスやライブラリの知見を集めており、その一環でMLKitの評価も行っています。MLKitの機能の1つに翻訳機能が存在します。検証の1つとして、この翻訳機能の実用性評価のためにニコニコ漫画アプリに適用もしてみました。この記事ではその際の結果について紹介します。
アプリチームのKです。Android版ニコニコ漫画 / 読書メーターの開発を担当しています。
日々アプリの価値向上を目的に様々な機能追加・改善を行っています。色々なサービスやライブラリの知見を集めており、その一環でMLKitの評価も行っています。MLKitの機能の1つに翻訳機能が存在します。検証の1つとして、この翻訳機能の実用性評価のためにニコニコ漫画アプリに適用もしてみました。この記事ではその際の結果について紹介します。
環境
次の環境下で検証しています。
| target | version |
|---|---|
| Android Studio | 4.1.2 |
| kotlin | 1.4.31 |
| com.google.mlkit:translate | 16.1.1 |
検証データ、及び実装について
宇崎ちゃんは遊びたい!の第1話のコメントを検証データとして利用しました。多くのコメントは日本語であり、今回は日本語のコメントを英語に翻訳する検証を行いました。翻訳を行う上で必要となるのが、言語間を処理するためのモデル(辞書のようなものをイメージください)であり、今回は日英言語モデルが必要となります。実装に関しては公式のドキュメント通りに行っており特別なことは行っていません。翻訳を実現するだけであれば特に難しいことはありませんが、翻訳処理時間・言語モデルの取り扱い方法については留意ください。それぞれ詳細については以降のセクションにて改めて記載しています。
アプリサイズ
まずはapk(debug build版)サイズを比較してみます。
|通常|Translate機能適用| |:--|:--| |23,194,097|29,186,610| 単位はバイト
サイズが30%弱増加しているのがわかります。またアプリサイズ自体に加えて言語モデル用にデータ領域も増加します。モデルサイズについてはドキュメントに次のように記載されていました。
Language models are around 30MB
実際にこの数値が正しいのか確認してみました。ここでは最初の動画にある通り日本語英語モデルのケースで確認しています。モデルの格納先ですが/data/user/0/{アプリパッケージ}/no_backup/com.google.mlkit.translate.models/en_jaとなります。
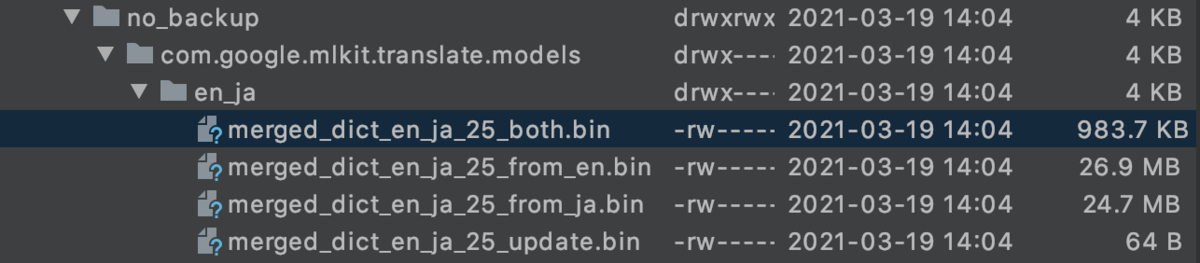
ざっくりと50MBほど消費しているように見えます。ドキュメント中の約30MBという値はあくまでも1モデル単位でのサイズであり、実際には翻訳元・先それぞれの言語モデルが必要となるため30 * n(モデル数)分消費することになります。
なお言語モデルですが、公式ドキュメントに書かれている通り必要になった際にダウンロードする形となります。またダウンロードしたモデルの削除も可能なため、不必要にアプリのサイズを膨張させることはありません。
処理時間
使用した端末は次の通りです。
| Property | Description |
|---|---|
device |
SO01M |
OS |
Android 10 |
SoC |
Snapdragon855 |
mem |
6GB |
執筆時点では対象作品のコメント数は844(1コメントあたりの最大文字数は60)で、この処理におよそ30秒ほどかかりました。
翻訳方法
translateのログを確認したところ興味深い内容が出力されていました。翻訳前後のセンテンスは次の通りです。
翻訳前: これは憎めないタイプのウザさ 翻訳後: This is a type of usa that can not hate
次のログは上記の翻訳が行われた際に出力されたログの一部を抜粋したものです。
The current system has NMT. 2021-03-18 19:07:46.963 7762-9029/jp.co.dwango.seiga.manga.android.debug D/native: mergeddicttrans.cc:1749 Sentence #0: これは憎めないタイプのウザさ 2021-03-18 19:07:46.963 7762-9029/jp.co.dwango.seiga.manga.android.debug D/native: mergeddicttrans.cc:1785 To be translated by NMT. 2021-03-18 19:07:47.028 7762-9029/jp.co.dwango.seiga.manga.android.debug D/native: mergeddicttrans.cc:1623 Sentence #0: これは憎めないタイプのウザさ 2021-03-18 19:07:47.029 7762-9029/jp.co.dwango.seiga.manga.android.debug D/native: mergeddicttrans.cc:1624 NMT preproc: ▁これ ▁は ▁ 憎 め ▁ない ▁タイ プ ▁の ▁ウ ザ ▁さ 2021-03-18 19:07:47.029 7762-9029/jp.co.dwango.seiga.manga.android.debug I/native: mergeddicttrans.cc:1632 NMT decoder output: 2021-03-18 19:07:47.029 7762-9029/jp.co.dwango.seiga.manga.android.debug I/native: mergeddicttrans.cc:1633 This is a type of usa that can not hate
コードを実際に確認したわけではありませんが、ログの内容的に翻訳元を形態素解析により構文解析、その後翻訳先言語へ変換という言語処理における一般的なアプローチを行っているように見えます。精度はモデル(辞書)に依存してくると思いますが、執筆時点ではリアルタイムに学習させる方法が見当たらなかったので、この機能を使う場合にはモデルの更新頻度に気をつける必要が出てくると思います。
翻訳精度
翻訳結果の精度を見ていきます。次のテーブルは一部抜粋した内容です。比較用にgoogle翻訳の結果も掲載してみました。
| 日本語 | 英語(ML-kit) | google翻訳 |
|---|---|---|
| w | Lol | w |
| 言わなくたって脳内再生くらいできるだろ(プロの豚) | I can play back in the brain without saying (professional pig) | You can even regenerate in the brain without saying (professional pig)| |
| 草 | Grass | grass |
| この子の体型ならバットに振り渡されるな | If this child body type is swing to the bat | If this child's body shape, don't be handed over to the bat |
| このコマの流れのゆっくりさに痛みが出てる(経験者視点) | Pains in the flow of this frame are painted (experienced viewpoint) | There is pain in the slow flow of this frame (experienced person's point of view) |
| 二十後半になるとありがちな反応 | Reaction that will be in the second half of the second | A common reaction in the latter half of the 20th |
| ウザ可愛いな | Uzaka cute | Uza is cute |
| 単行本出たら買うよ | I will buy it as a single ride | I'll buy it when the book comes out |
| 丈さん連載おめでとう | Congratulations on Length | Congratulations on Mr. Takeshi's serialization |
| アニメ化も期待したいです! | I also want to expect animation! | I also want to expect animation! |
個人的にはMLKitにて"w"が"lol"に変換されたことに驚かされましたが、結果は予想通りというかそこまで良くなかったです。とは言えgoogle翻訳の結果もそれほど良いとは言えないものなので抽出したセンテンスに問題があったかもしれません。
適用後イメージ
次の画像はTranslate機能を使いコメントを翻訳(日本語 to 英語)しているイメージ画像となります。
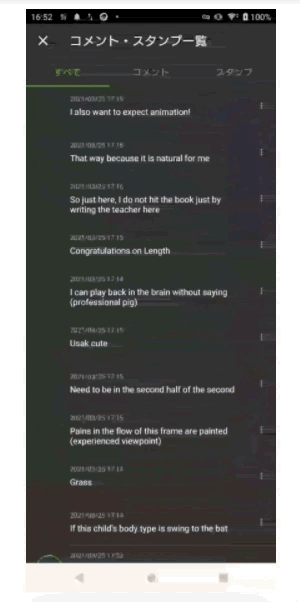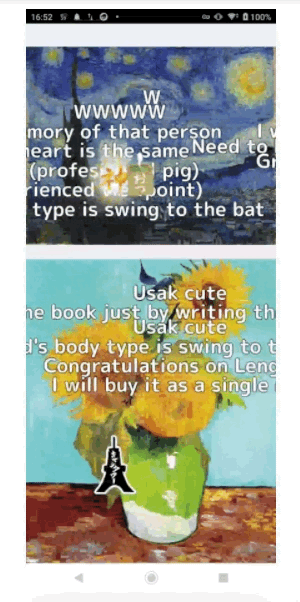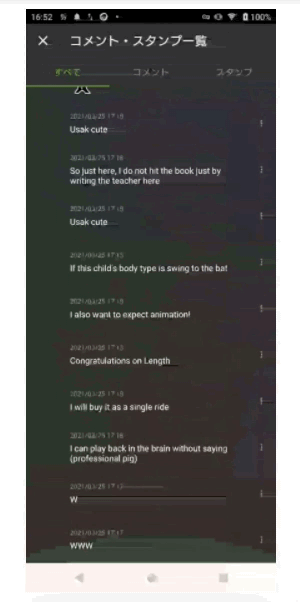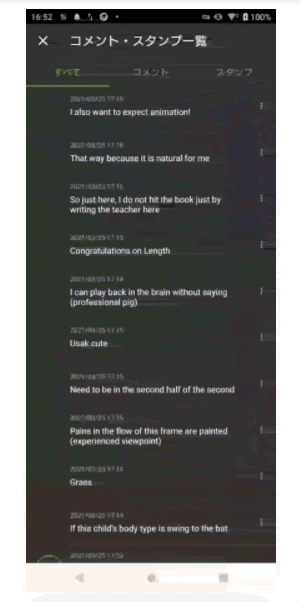
translate機能まとめ
現状は処理時間・精度等を考えると漫画アプリでの利用は厳しそうです。面白い機能であることは間違い無いので今後もフォローしていきたいと思います。